Introduction
I provided a general overview of large language models and generative AI in a recent post. As AI momentum continues to grow, there are now more announcements in areas which are closer to our domain.
Here I want to look a little bit more at some examples of scholarly or cultural large language models (LLMs). It is not at all a comprehensive review, rather a sampling of indicative initiatives. The focus is on LLMs themselves and the importance of curated data to these initiatives, rather than on the parallel proliferation of AI-based applications which use the LLMs.
There is now a diverse and expanding universe of LLMs. There are foundation models from large established players (e.g. Google and Microsoft, individually and in its support for OpenAI) and from several startups (e.g. Anthropic), some of which are developing into platforms for others. There are platforms which make these and other models available in managed environments (e.g. Amazon, Microsoft, Fixie). There is a flourishing ecosystem around open source LLMs which are growing in capabilities, some targeted at more affordable computational environments (many of these are aggregated on Hugging Face, an important AI provider of infrastructure and services).
And then there is a variety of domain specific initatives developing models, or training more general models, for specialised communities or applications (e.g. medicine, finance, biosciences).
The composition, transparency, documentation and representativeness of these models are important issues given known concerns. There are issues around IP and reuse, concentration of economic and cultural power, exploitation of hidden labor, as well as around environmental impact, impact on employment, and social confidence and trust. Given the potential impact regulation is being considered by many regimes.
These issues are of special concern in scholarly and cultural domains, where transparency, equity and respect for cultural particularity and expression are important. For research purposes, results need to be reproducible. In this context, it is interesting to see the emergence of several models specialised to these domains, and some attention to the more careful curation of training and tuning data. We can expect to see more activity here, across scholarly and cultural interests.
Even in research and cultural contexts, the use of AI and LLMs will range widely. For a sense of developments in big science and high performance computing see this report based on a series of workshops organized by the (US) national laboratories. At a different scale, see for example this discussion of the potential use of AI in computational social sciences [pdf]. And, for a telling example of issues with current foundational LLMs see this paper about ways in which book literature in training data disproportionately leans in particular directions: Speak, Memory: An Archaeology of Books Known to ChatGPT/GPT-4 [pdf].

Recent AI overview post: large language models, generative AI and surrounding developments
As a lead-in, two recent announcements caught my eye.
LibraryThing and ProQuest have introduced an experimental recommender service, Talpa, assocated with the Syndetics Unbound product. It is designed to answer those questions where some characteristics of an item are known, but maybe not the actual title or other details. I thought it was interesting for three reasons. First, it shows what is possible for a small group like LibraryThing to achieve based on leveraging emerging AI platforms, in this case ChatGPT and Claude AI from Anthropic. Second, it is an example of how apps will be built by articulating elements from various services. The LLMs are queried for books. But the LLM text comprehension and manipulation services are also used to process the incoming queries. Bibliographic data from ProQuest and LibraryThing is used to validate the existence and details of materials. And third, those existing sources of domain-specific and highly curated data are used to improve quality and mitigate the effects of hallucination.
The second is an announcement from Clarivate about a partnership with leading AI company AI21Labs. There are not many details in the release, but it emphasises the deep reservoir of curated content that Clarivate manages, the provision of conversational interfaces, and the tools for language 'comprehension and generation' that AI21 brings to the table.
Embedding generative AI to enable market-leading academic conversational discovery // Clarivate
Given its scale, I had wondered whether Clarivate might develop its own language model (see discussion of the scholarly communication service providers below), in the way that Bloomberg, say, has done. Partnering in this way seems sensible and it is likely that we will see other agreements between service providers and AI platform providers. The press release focuses on the scholarly and library interests of Clarivate, mentioning recommendations and conversational search in discovery.
It will provide students, faculty and researchers with rapid access to detailed and contextual information and answers along with more personalized services to offer benefits such as relevant recommendations. Conversational search across discovery solutions will allow students to intuitively interact with discovery services, aggregated databases and collections to receive more relevant, diversified results and services based on trusted content. // Clarivate
So we potentially see three levels here: using LLM APIs to build services, partnering with an LLM provider where there is some scale, or developing an LLM oneself. Here I am looking at some examples of the third level.
Quick AI recap
For orientation and context I provide the summarising final remarks from the earlier AI overview post here, very slightly amended. Skip to the next section if this is not of interest.
Four technology capacities seem central (especially as I think about future library applications):
- Language models. There will be an interconnected mix of models, providers and business models. Large foundation models from the big providers will live alongside locally deployable open source models from commercial and research organizations alongside models specialized for particular domains or applications. The transparency, curation and ownership of models (and tuning data) are now live issues in the context of research use, alignment with expectations, overall bias, and responsible civic behavior.
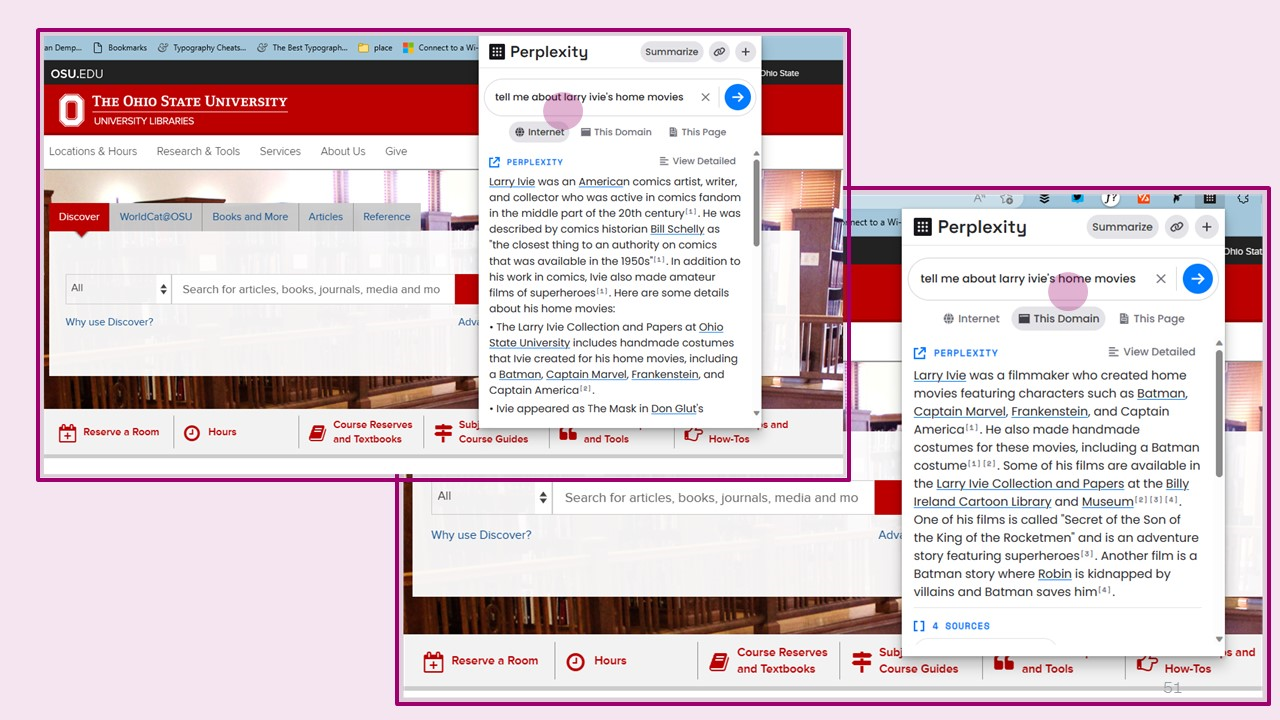
- Conversational interfaces. We will get used to conversational interfaces (or maybe 'ChUI' - the Chat User Interface). This may result in a partial shift from 'looking for things' to 'asking questions about what one wants to know' in some cases. In turn this means that organizations may begin to document what they do more fully on their websites, given the ways in which services will combine discovery and the textual abilities of LLMs to process, summarise and generate text, or pass it to other servcies. For an interesting example, see how the perplexity.ai app/extension can work over a local website (see the screenshots below).
- Agents and workflows. The text interfacing capacities of LLMs will be used more widely to create workflows, interaction with tools and knowledge bases, and so on. LLMs will support orchestration frameworks for tools, data and agents to build workflows and applications that get jobs done.
- Embeddings and Vector databases. Vector databases are important for managing embeddings which will drive new discovery and related services. Embedding APIs are available from several organizations. (Embeddings are representations of text elements which supports semantic applications like classification, retrieval, translation, and so on. One can compute 'similiarity' between embeddings. They underly many of the services we are now seeing emerge.)
Several areas stand out where there is a strong intersection between social policy, education and advocacy:
- Social confidence and trust: alignment. Major work needs to be done on alignment at all levels, to mitigate hallucination, to guard against harmful behaviors, to reduce bias, and also on difficult issues of understanding and directing LLM behaviors. However, there will be ongoing concern that powerful capacities are available to criminal or political bad actors, and that social trust and confidence may be eroded by the inability to distinguish between human and synthesized communications.
- Transparency. We don't know what training data, tuning data and other sources are used by the foundation models in general use. This makes them unsuitable for some types of research use; it also raises more general questions about behaviors and response. We also know that some services capture user prompts for tuning. Tolerances may vary here, as the history of search and social apps have shown, but it can be important to know what one is using. Models with more purposefully curated training and tuning data may become more common. Documentation, evaluation and interpretability are important elements of productive use, and there are interesting intersections here with archival and library practice and skills.
- Regulation. Self regulation and appropriate government activities are both important. The example of social media is not a good one, either from the point of view of vendor positioning or the ability to regulate. But such is the public debate that regulation seems inevitable. Hopefully, it will take account of lessons learned from the Web 2.0 era, but also proceed carefully as issues become understood.
- Hidden labour and exploitation. We should be aware of the hidden labour and exploitation involved in building services, and do what we can as users and as buyers to raise awareness, and to make choices.
The return of content: the value of expertise and verified data
Emad Mostaque, CEO of Stability AI, compares the 'junk food diet' of the large language models with a more 'organic, free-range AI':
As the saying goes, you are what you eat, so we should feed these models better things.
No more web crawls, no more gigantic datasets with all sorts in [...], instead lets do good quality datasets.
He argues that there should be more emphasis on good quality inputs which reduces the need for alignment of outputs where models are fine tuned after training.
Let's all get together to build good quality, open, permissive datasets so folk don't need to clog the arteries of these GPUs with junk, which often causes dreaded loss spikes. // On hallucinations, junk food & alignment
In the AI overview post, I noted the interesting argument by Alex Zhavoronkov in Forbes that content generators/owners are the unexpected winners as LLMs become more widely used. The value of dense, verified information resources increases as they provide training and validation resources for LLMs in contrast to the vast uncurated heterogeneous training data. Not unsurprisingly, he points to Forbes as a deep reservoir of business knowledge. He also highlights the potential of scientific publishers, Nature and others, whose content is currently mostly paywalled and isolated from training sets. He highlights not only their unique content, but also the domain expertise they can potentially marshall through their staffs and contributors.
 Alex Zhavoronkov, PhD
Alex Zhavoronkov, PhD
The balance between specialized curated data and more general internet data is something that will be decided in particular contexts, especially as there is more experience and R&D across the range of training and tuning options.
With that as background, here are some notes about several initiatives. The first is a speculative look at the scholarly communication service vendors. This is followed by descriptions of several LLM initiatives in the scholarly and cultural space.
① Speculative: the scholarly communication service vendors
It is interesting to consider for a moment the potential role of Elsevier, Digital Science/Holtzbrinck and Clarivate. In the absence of a general industry category I call these three organizations scholarly communication service vendors. They have a very interesting place in the current scholarly ecosystem given the range of their data and workflow resources.
Elsevier and the Holtzbrinck Publishing Group, are major publishers who have evolved a range of scholarly workflow, productivity, analytics and other services alongside their publishing activity. Clarivate has a broad portfolio, across several domains.
Each of these groups offers some selection of publishing, research workflow, research evaluation and analytics and other services. The internal evolution of each has been quite different, in terms of service development, acquisition, and so on, as is how the constituent parts are configured and presented to meet market needs. Importantly, as I have noted before, each is also building a research graph or representation of research activity which supports, and is supported by, other services.
Each presents a graph-based view of the core of scientific knowledge as represented in the literature, through Scopus, Web of Science and Dimensions, respectively. Increasingly they want to document research entities (researchers, outputs, organizations, etc), they want to analyze research knowledge as represented by those entities, and they want to visualize research patterns and relationships. And then to provide a variety of decision support, discovery and evaluative services on top of those structures. // Workflow is the new content
Elsevier and Digital Science/Holtzbrinck have assembled a range of services which involve data, workflows and expertise at multiple points of the research lifecycle. However purposeful this was in retrospect, it certainly now seems strategically advantageous against the background of current developments. Notably, what comes across – to varying degrees and in different ways – is a perspective which sees data and workflow services as connected parts which in turn need to be connected into the broader fabric of research and learning.
Elsevier, for example, has moved strongly both upstream and downstream: upstream into research evaluation and analytics in recent years, or what it calls 'research intelligence', and downstream into individual researcher workflows. This portfolio now includes scientific publications, a research graph (Scopus and other resources), research data management/research information management/institutional repository services, a set of research analytics and impact measurement services, researcher productivity services, preprints services, and so on.
... what comes across [...] is a perspective which sees data and workflow services as connected parts which in turn need to be connected into the broader fabric of research and learning.
Holtzbrinck Publishing Group also brings together a major scientific publishing engine, Springer Nature, with a portfolio of high profile workflow, productivity and analytics applications across the research life cycle (for example, Altmetric, Readcube, Symplectic Elements, Figshare, Labguru, and so on). While they appear to be managed at arms length, it will be interesting to see whether and how Digital Science and Springer Nature work together given the scale of the current challenge and opportunity.
Clarivate has a different profile again. It has significant content resources across several domains. In the scientific and research arena, it also has a curated research graph (Web of Science) and associated resources, and the recent acquisition of ProQuest adds other content and workflow resources. As noted above, Clarivate has declared a partnership with AI21 and it will be interesting to see how they leverage that in services.
I have emphasised the composition of these three groups because they have
- the scale and expertise to do work in this space,
- major reservoirs of scientific literature, representing a significant part of the scientific record,
- prior investment in structured data and a research graph, manifest in flagship products
- the ability to leverage networks of expertise, and
- a range of workflow services gathering current information and analytics.
What could they do?
We will likely see the general further incorporation of capacities which assist at various stages of the workflow. The scholarly AI taxonomy expanded on here provides a reasonable framework for thinking about this: one can imagine services around discovery, entity extraction, summarization, trend analysis, and so on.
But beyond this it is interesting to think about what more they could do from a systemwide perspective, and what level of investment they bring to the opportunity.
- Strategic partnership with LLM provider. We have yet to see what Clarivate and AI21 do together. LexisNexis, Elsevier's sibling company, uses several LLMs and its own data in its Lexis+ AI service. Digital Science uses AI in several services, and it recently announced a management reorganization "to reflect its current steep growth trajectory and further develop its market-leading capabilities in Artificial Intelligence (AI) and related technologies." It promises further product announcements to follow this year. Is there scope for a significant reciprocal partnership between Elsevier or Digital Science and one of the other emerging AI players (Cohere or Anthropic, for example)?
- Develop a specialist LLM to support scholarly work? Use specialist data sets to tune existing language models? The black box nature of the popular LLMs may disincline some to use them for research and scholarly work; these organizations could address that by building models based on their known research graphs and other data.
- License or offer content and their research graphs to LLM developers. Make details public.
- Build new ways of analysing the scholarly literature, doing ranking and measurement, providing discovery services. The semantic capacities offered by the embedding model make it interesting to think what they could do here.
- We are likely to see conversational or chat interfaces to many services (ChUI), as the focus shifts from looking for things to answering questions.
- We are moving quickly into the third front of open access, where the discussion is not about individual articles, journals, publishers or deals, but about AI-powered exploration of the research space (to include literature, data, people, organizations, ...). (Taking Green and Gold as first two fronts. One might add Diamond, and say the fourth front, but diamond doesn't have the same scale?) This is worthy of much more discussion, but these organizations are now well placed to offer a new level of access. But to whom and on what terms?
Open access is already a complex topic. There are multiple paths with no single or agreed destination. From a library policy point of view, I think this last point is very important. If (or when) interaction with the literature shifts in this way, then thinking about what open access means also needs to evolve.
If (or when) our interaction with the literature shifts in this way, then thinking about what open access means also needs to evolve.

RELX, Elsevier's parent publishes papers on their AI position and principles
② Culture and language plus public infrastructure: the National Library of Sweden
The National Library of Sweden has been developing Swedish language models based on its collections. It is also cooperating with Nordic national libraries in the Nordic languages, and more broadly with other germanic languages. The National Library is also working within the public high performance computing environment of the European Union [video].

AI initiatives are part of a larger project to digitize and make available in readily processable ways the collections of the library. Applications include transcription of handwritten documents into digital text, spelling correction, tagging by topic, author and time period. They hope also to generate descriptions of video.
An important aspect of the work here is the Swedish language and cultural context.
The National Library of Sweden is an admirable pioneer here. It does prompt the question about what long term public cultural or research provision there will be in this space and what level makes sense.
“They can ask questions like ‘what the sentiments in headlines in newspapers during the conflict in Ukraine are’,” says Börjeson. “It was sad, then positive last fall, then negative again. You can have that kind of quantitative questions without actually accessing data.” // ITPro
Other players here might be other national libraries, museums and cultural institutions.
There are also some non-profits in the library space who have the scale to do some work here, manage important reservoirs of data, and may be able to attract philanthropic support. Think of the combined bibliographic assets of Ithaka, HathiTrust and OCLC for example. The Internet Archive also has some scale in terms of infrastructure, data and resource.

National Library of Sweden on Hugging Face
An important aspect of the work here is the Swedish language and cultural context. Although there have been some attempts to broaden scope, existing LLMs will tend to be based on the characteristics of the Internet training data used, which, when compared to the whole of human knowledge, will lean to the English language as well as to more well off countries. This is an important issue given how LLMs are being used in knowledge and question answering applications. The National Library is making models based on the Swedish language available, as well as on its culture, history, current attitudes, and so on. This is important in the global context. Again, it raises the question of whether national libraries in cultural and language communities not strongly represented might have a role to play with other partners.
③ CORE: working with the largest publicly available reservoir of open access articles
CORE is an open access aggregation service provided by the Open University in the UK. It recently announced that it would be building an AI-based application with what they claim is the world's largest available reservoir of open access articles, sourced from repositories and journals.
The CORE-GPT application is a step change in academic question answering. Our key development is that the provided answer is not just drawn from the model itself, as is done with ChatGPT and others, but is based on, and backed by, CORE’s vast corpus of 34 million open access scientific articles.
They note some of the issues with large language models, and suggest that these would be mitigated by working with their corpus of articles.
CORE-GPT offers a solution to this problem. By ensuring that answers given are derived exclusively from scientific documents, this largely eliminates the risk of generating incorrect or misleading information. Further, by providing direct links to the scientific articles on which the answer is based, this greatly increases the trustworthiness of the given results. // CORE
There are not a lot of details available, so it will be interesting to see what they are implementing. One imagines that they will still have to manage hallucinations, even if scholarly ones.
There are various scenarios which could be implemented in cases like this. They could build their own LLM. They could use Cohere or OpenAI, say, to provide embeddings to support querying, clustering, visualization, and so on. They could use the language processing and conversational capabilities of ChatGPT or another service in association with searches over their content. I anticipate that we will see a lot of experiment as content providers explore how they can leverage AI services in different ways. CORE is not a large organization: it might make sense to partner with other organizations with an interest in this area.
In a parallel development, they are exploring a membership model as their current Jisc funding comes to an end. This raises the question of how initiatives like this sustain themselves, in the absence of direct public support.
A very interesting and detailed overview of technical, data and related Core characteristics and challenges was recently published in Nature Scientific Data [pdf].
④ OLMo, a model for scientific research
Semantic Scholar is built by a team within the Allen Institute for AI (AI2). It has been building a scholarly discovery service for some time, already using AI to help identify entities and create relationships in the scientific literature. AI2 has now announced a scientific LLM, AI2 OlMo (open language model).
As a transparent, collaborative, nonprofit institution, we are well-positioned to build a language model that is truly open and uniquely valuable to the AI research community. Our OLMo endeavor will include more than just building an open language model — we’re purposely building a platform that will allow the research community to take each component we create and either use it themselves or seek to improve it. Everything we create for OLMo will be openly available, documented, and reproducible, with very limited exceptions and under suitable licensing. The artifacts released as part of the OLMo project will include training data, code, model weights, intermediate checkpoints, and ablations. A release strategy for the model and its artifacts is in development as part of the project. We also plan to build a demo and release interaction data from consenting users. // AI2
This is significant given the track record of Semantic Scholar and AI2, the commitment to open, and the scale and expertise AI2 brings to the task. It has the potential to be the basis for a variety of scientific or research models.
Additionally, AI2 is partnering with MosaicML, a company which has developed and released several open large language models.
As well, AI2 will openly share and discuss the ethical and educational considerations around the creation of this model to help guide the understanding and responsible development of language modeling technology. // MosaicML
What other non-profit entities could do similar work? Especially if foundation money were to be support the activity. It is interesting to wonder about Google given some of its assets. Are Google Books and Google Scholar mobilised within Google's LLM work already? Is there scope for an LLM which leverages that scholarly and bibliographic investment? Of course, Google would probably not approach it with the openness of AI2.
⑤ A note on Intel/Argonne
Intel and Argonne National Laboratory have announced plans for models to support the major scientific activity at the US national laboratories and elsewhere. There is very little detail in the announcement, but it will leverage Aurora, the high performance computing capacity at Argonne, being built with Intel.
These generative AI models for science will be trained on general text, code, scientific texts and structured scientific data from biology, chemistry, materials science, physics, medicine and other sources.
The resulting models (with as many as 1 trillion parameters) will be used in a variety of scientific applications, from the design of molecules and materials to the synthesis of knowledge across millions of sources to suggest new and interesting experiments in systems biology, polymer chemistry and energy materials, climate science and cosmology. The model will also be used to accelerate the identification of biological processes related to cancer and other diseases and suggest targets for drug design.
Argonne is spearheading an international collaboration to advance the project, including Intel; HPE; Department of Energy laboratories; U.S. and international universities; nonprofits; and international partners, such as RIKEN. // Intel
There is relevent background in the Advanced research directions on AI for science, energy and security report mentioned above [pdf]. It is interesting given the federal support, the involvement of Intel (who faces strong competition now from Nividia in the AI space), and the ambition. We will have to wait to see more details about general availability, openness, and so on.
Many countries have public science infrastructure support. It will be interesting to see what LLM support might emerge in those contexts.
⑥ Language models redux
Finally, based on this, some things to note in the general context of large language models:
- Curation is in line with strong advocacy for greater transparency around both training and fine-tuning data. This is important for reproducibility in research, for reducing bias or harm, for making specialist or underrepresented perspectives available. At the same time, developers want to preserve the general textual abilities of such models, developed through training on large amounts of data.
- Some of the data of scholarly interest is behind paywalls, and has not been available as part of training data for current models. Publishers and other content providers have decisions to make about whether to license data to the large model providers, to create models themselves, or to create new partner opportunities. The Washington Post analysed Google's C4 data set which has been used to train several models. Interestingly, it includes some data from Springer, Elsevier and Wiley although we do not know which data or under what terms.
- Certainly, the importance of curated data sets in training LLMs has introduced a new factor for content providers, and one is reminded of discussions between Google and news providers in the early days of web crawling. One interesting category of service is the community forum style service such as Reddit or Stack Overflow, whose value is created by open participation on a strong network platform. They have said they will charge to be ingested for training purposes. There has been some suggestion in relation to scholarly data that LLMs may enhance an 'open' advantage, however it is really too early to say in a rapidly evolving data environment.
- Open scientific, cultural and other material have been part of training data. For example, The Washington Post analysis shows Internet Archive, arXiv and Plos data in C4. However, it is mixed with other data.
- There are various ways in which one might specialise an LLM. BloombergGPT uses a mix of its deep historical reservoir of proprietary financial data and general materials in its training and reports good results. One can fine-tune an existing model to a particular domain. Google 'aligned' its Med Palm 2 model with specialist medical data. Or one could create a specialist model like the National Library of Sweden's.
- The LLM space is dominated by commercial players, with some collaborative, non-profit and educational contributions. There is little direct public provision or support at the moment (a model which is more common outside the US), although certainly public sources of funding have underpinned R&D and other activities. Understanding issues around sustainability, where can we see LLMs from the cultural, scholarly and non-profit sectors emerge?
Finding aids are especially interesting in this context. Maybe they will come into their own as new computational users take advantage of the context and connections they provide.
Conclusion
As the AI ecosystem continues to diversify, libraries have much to think about. I will return to thoughts about libraries and library services, but here are three thoughts specifically about libraries and LLMs in conclusion.
- Advocacy and policy. The way in which we create and use knowledge resources is changing. I mentioned the potential third front of open access above as interaction with the scholarly literature is progressively AI-enabled. It will be important for libraries and library representative and advocacy organizations to track and respond to the computational context of literature use.
- Informed consumers. Libraries will be buying products which are AI-enabled in various ways. They should use that economic weight to argue for good practices, in particular around the social concerns that they raise and around appropriate transparency and documentation of models and data.
- The documentation and discovery deficit. Organizations are now used to search engines as consumers of their web content, and there has been a big focus on SEO and related topics. As we see the combination of search technology, LLM text processing and generation capacities, and conversational interfaces, we will potentially see another shift in how organizations make content available. We will likely see more attention to fuller documentation on the web. I recently discussed the documentation and discovery deficit in library operations. This may become more of an issue in this context (see the perpexity.ai example above). It might be advantageous for libraries to do more work in contextualising their services, in contextualising resources with learning contexts (through resource guides, reading lists, ...), in contexualising special collections with exhibitions, in documenting hidden collections or materials from under-represented communities, and so on. Finding aids are especially interesting in this context. Maybe they will come into their own as new computational users take advantage of the context and connections they provide.
Feature picture: The feature picture is a piece by A.K.Burns, which I took at an exhibition of her work at the Wexner Center for the Arts, The Ohio State University. The photograph on the AI overview post is of the same piece, but taken from the other side (with a different color wall in the background).
Acknowledgement: I am grateful to Karim Boughida and Ian Mulvany for commenting on an earlier draft.