The plurality of Flann O'Brien
Names and identities are a major focus of interest for OCLC Research. I adapt this discussion of our work in this area from the recent OCLC Research Quarterly Highlights.
We know very well that names are not always straightforward. Brian O’Nolan and Brian Ó Nualláin are the English and Irish versions, respectively, of the name of the person who is more commonly known to us as the author Flann O’Brien.
But things are more complicated. Flann O’Brien was the ‘identity’ he chose when writing novels in English. As the prolific author of satirical columns in the Irish Times, he was known as Myles na gCopaleen, under which identity he also wrote an Irish language novel (and it should be noted that this turns up under different spellings, Myles na Gopaleen, for example). I take it that Flann O’Brien and Myles na gCopaleen are examples of what ISNI (more of which later) calls ‘public identities’ for Brian O’Nolan. Of course, it does not stop here, as Flann O’Brien was also known by several other names.
More generally, even if most people’s names and identities are less complicated than this, there is not a one-to-one relationship between names and people. This means that the relationship between people and their names and identities has become something that is managed in a variety of places. Of course, different choices can be made in those places. If I do a search on Wikipedia for either Flann O’Brien or Myles na gCopaleen, for example, I get directed to the page for ‘Brian O’Nolan’. Wikipedia directs us to the person Brian O’Nolan, rather than to any of his assumed identities. Libraries have for a long time had an apparatus to manage this plurality: authority control. And national library authority files have different practices in how they roll names up to one or more identities.
Authority control and VIAF
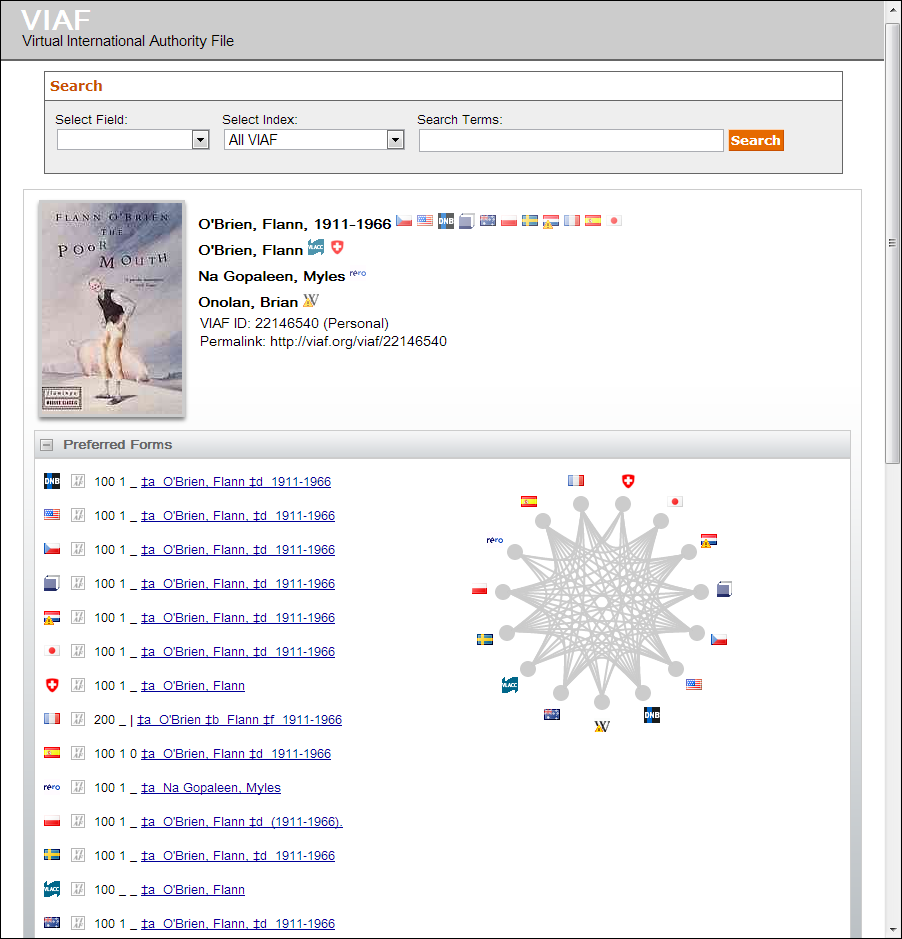
Authority control has typically been organized on a country by country basis: national libraries organize national authority files. As the network unifies information spaces globally, purely national files have less utility. Recognising this issue, OCLC Research has been working with national libraries around the world to synthesise authority files into what we call the Virtual International Authority File, VIAF. VIAF now brings together names from those files into 24 million clusters, and assigns each of these a unique ID. Matches are not made simply on name text strings–contextual data from the authority files (e.g., birth date) and associated bibliographic data are also used. Further work is being done to increase the value of this consolidated resource. For example, the VIAFbot initiative creates links between Wikipedia and VIAF, inserting a VIAF link on appropriate Wikipedia pages. And VIAF now treats Wikipedia as a contributory source, ingesting names from Wikipedia alongside names from national authority files. In this way, there is a direct, actionable link between the global, addressable knowledge base that (the English) Wikipedia has become and library files, enhancing the value of each. The Wikipedia page for Brian O’Nolan has a link to the VIAF entry for Flann O’Brien. Importantly, from this we can assert that the “thing” or “person” described by https://en.wikipedia.org/wiki/Brian_O’Nolan is the same as the “thing” or “person” described by https://viaf.org/viaf/22146540/. We are looking at other language Wikipedias also.
VIAF has quickly become a major source of data about names. It gives a unique identifier to those entities–people, organizations, and others–which are the creators or subjects of works, gathers names which designate them, and contextualizes them with associated metadata. OCLC and the participating national libraries hope to see VIAF become an important backbone reference in the emerging web of data. And for this reason, we have made it openly available as linked data.
VIAF, ISNI, Orcid
Of course, there are also other important initiatives, notably ISNI and ORCID. As the web becomes more central to scholarly and cultural activity, and as more information work is automated, identity and disambiguation are increasingly important. People are resources which need to be discoverable, referencable, and relatable. Accordingly, names and their relationship to the people they designate has become a key interest in the cultural, educational and creative fields.
Because of our work with VIAF we are closely connected with both ISNI and ORCID. The International Standard Name Identifier (ISNI) is an ISO standard (ISO 27729) that uniquely identifies “the identities used publicly by individuals or organizations involved in creating, producing, managing and distributing content.” It is managed by a consortium of national libraries, rights organizations and others. The ability to unambiguously designate a person is important in a rights environment. VIAF provided data to seed the ISNI pool of people data and OCLC provides the infrastructure to manage ISNIs. ISNIs have begun to be added to VIAF. ORCID emerges from the scholarly publishing arena where the consistent identification of researchers has always been an issue. Here again, as more services are built on the programmatic manipulation of data about publications, researchers and institutions, unambiguous designation has become a goal. OCLC Research participates on the ORCID Board and the relationship between VIAF and ORCID is being discussed.
We expect to see various relationships between ISNI, VIAF and ORCID as they evolve.
Other names initiatives
Alongside this involvement in these important formal initiatives, we have some other important interests in names. These include:
- The source of information about names in the above initiatives is the creator themselves, or expert metadata creators. However, we also expect to complement this work by programmatically identifying names. We are exploring automatic recognition, extraction, and disambiguation of named entities (e.g., the names of people, places, and organizations) from digital texts. This work will be increasingly important, as manual description methods will not scale.
- We provide Worldcat Identity pages into the Worldcat.org environment. Here is the page for Flann O’Brien: https://www.worldcat.org/wcidentities/lccn-n50-1905. Worldcat Identities has a summary page for every name in WorldCat (currently over 40 million names) including named persons, organizations and fictitious characters. The pages include information derived from WorldCat and other sources (including VIAF) alongside unique data derived or created through a variety of special processing activities (e.g., WorldCat Identities provides statistical data about how widely held a work is). A typical WorldCat Identities page will include a list of most widely held-by-libraries works by and about the identity, a list of variant forms of name the identity has been known by, a tag cloud of places, topics, etc. closely related to works by and about the person, links to co-authors, and more. While Worldcat Identities and VIAF are developed from different directions, we are looking at closer links between them.
- We have been working with a group of Syriac scholars, looking at issues around accepting a feed of names into VIAF from a scholarly community rather than from a national authority file. See https://hangingtogether.org/?m=201303 for some discussion. In general, it is likely that VIAF will synthesise data from other additional sources which go beyond national authority files.
- Given growing library interest in the names and identities of their institution’s researchers, the partial nature of national authority files (they typically only include creators of works which have been catalogued), and the emerging variety of identifier approaches, we have instituted a working group to explore issues around names, researchers, libraries, and national authority files. https://oclc.org/research/activities/registering-researchers.html The initial aim is to produce a report which looks at the role of authority files as library and researcher needs change.
We are pleased to be doing this important work as part of an emerging infrastructure around names and identities. We welcome enquiries or comments–to me or directly to colleagues working on these initiatives. Further details can be found on these pages:
- VIAF – https://www.oclc.org/viaf.en.html
- WorldCat Identities – https://www.oclc.org/research/activities/identities.html
- Registering Researchers in Authority Files – https://oclc.org/research/activities/registering-researchers.html
Picture: The picture is a screen shot of part of Flann O'Brien's Viaf entry.
Note: Amended cosmetically on 31 March 2021 with picture, headings and improved spacing.